Le RGPD introduit une obligation générale de sécurité des données personnelles et impose ainsi à chaque responsable de traitement et sous-traitant, de mettre en œuvre des mesures de sécurité techniques et organisationnelles appropriées afin de garantir un niveau de sécurité adapté au risque.
Nous allons dans cet article, faire un zoom sur deux mesures de sécurité, qui sont parfois confondues, à savoir, la pseudonymisation et l’anonymisation des données.
La pseudonymisation
Qu’est-ce que la pseudonymisation ?
La pseudonymisation est une opération introduite par le RGPD, qui consiste à remplacer un attribut par un autre, visant ainsi à limiter le risque d’identification directe d’un individu. En d’autres termes, des données directement identifiantes (comme le nom ou le prénom) sont remplacées par des données indirectement identifiantes, (comme par exemple un alias, un numéro, etc…).
Grace à la pseudonymisation, il ne sera donc plus possible d’attribuer des données à une personne physique identifiée, sans information supplémentaire. « La pseudonymisation permet ainsi de traiter les données d’individus sans pouvoir identifier ceux-ci de façon directe. » (CNIL).
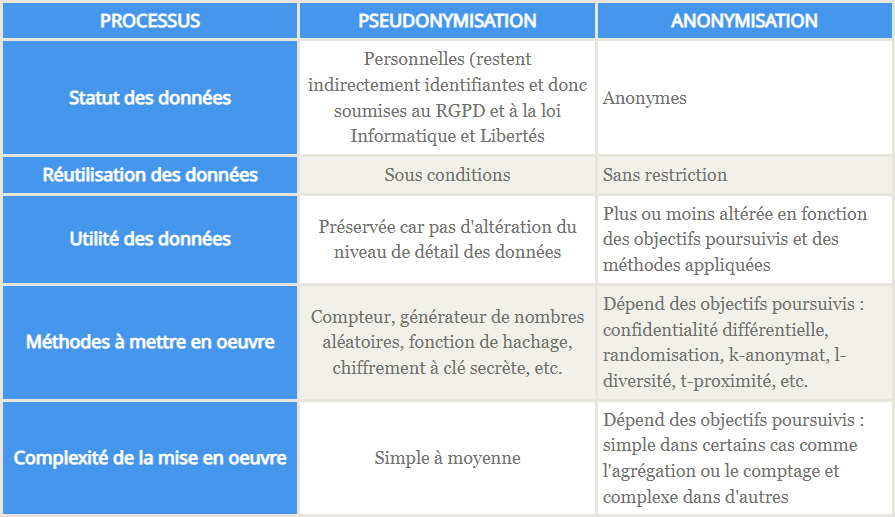
En revanche, à l’inverse de l’anonymisation, la pseudonymisation est une opération réversible. Il sera possible à l’aide d’informations supplémentaires, de retrouver l’identité des personnes dont les données ont été pseudonymisées. Par exemple, par l’intermédiaire des tables de conversation qui mettent en relation les données directement identifiantes et les pseudonymes, il sera possible de retrouver l’identité des personnes concernées.
De ce fait, les données pseudonymisées sont considérées comme des données personnelles et leur traitement est donc soumis aux exigences du RGPD.
Dans quel cas pseudonymiser des données ?
Une organisation peut avoir recours à la pseudonymisation lorsqu’elle souhaite assurer la sécurité des données traitées, tout en préservant leur utilité. C’est une technique qui permet ainsi à un organisme de masquer l’identité des personnes concernées à des tiers, tout en conservant des données exactes au niveau individuel.
Autrement dit, l’organisation a identifié une nécessité à conserver des données individuellement précises pour une réidentification ultérieure, mais le traitement effectué ne nécessite pas une identification directe des personnes concernées.
Comment pseudonymiser des données ?
En pratique, il existe plusieurs techniques pour pseudonymiser des données.
- Le compteur, par exemple, est une technique qui repose sur la création de pseudonymes. Cette technique consiste à remplacer les informations directement identifiantes, par un nombre qui aura été défini par un compteur. Il sera important que les nombres créés par le compteur ne soient jamais identiques, afin que les données initiales ne soient pas rattachées à un même pseudonyme.
- Le chiffrement à clé secrète, est un autre exemple de pseudonymisation. Cette technique, consiste à chiffrer les données directement identifiantes afin de les rendre incompréhensibles. Seulement l’organisme détenteur de la clé, sera en mesure de déchiffrer les données et ainsi de lire les données directement identifiantes.
- Etc…
Pour choisir une technique de pseudonymisation, il sera important de prendre en compte le niveau de protection des données requis, ainsi que l’utilisation qui sera faite des données par l’organisation.
Dans le cas des deux exemples de pseudonymisation susmentionnés, il est important que les informations supplémentaires qui permettent d’identifier la personne, soient conservées séparément et soient soumises à des mesures de sécurité. Par exemple, en cas d’accès non autorisé à la clé secrète, un renversement non autorisé de la procédure de pseudonymisation pourrait se produire, pouvant alors entrainer des dommages et préjudices pour les personnes concernées.
L’anonymisation
Qu’est-ce que l’anonymisation ?
La CNIL présente l’anonymisation comme « un traitement de données personnelles qui consiste à utiliser un ensemble de techniques de manière à rendre impossible, en pratique, toute réidentification de la personne, par quelque moyen que ce soit. »
En d’autres termes, l’anonymisation a pour objet de supprimer le caractère identifiant d’une donnée ou d’un ensemble de données. Contrairement à la pseudonymisation où il est possible de retrouver l’identité d’une personne si l’organisme dispose d’informations supplémentaires, l’anonymisation est irréversible : une fois que des données ont été anonymisées, il sera impossible pour l’organisme de réidentifier les personnes. Les données sont considérées comme anonymes.
C’est pour cela, que les données anonymisées ne sont plus considérées comme des données personnelles et qu’elles peuvent être conservées sans limitation de durée.
Si à l’issue du traitement « d’anonymisation » il reste possible de retrouver l’identité d’une personne, cela signifie que l’organisation n’a pas procédé à une technique d’anonymisation telle que le définissent la CNIL et le G29.
Dans quel cas anonymiser des donnés ?
L’anonymisation est un moyen de conserver et d’utiliser des informations qui présentent un intérêt, par exemple commercial, sans porter atteinte à la vie privée des personnes concernées. Par exemple, à l’issue d’un événement organisé par une entreprise, cette dernière peut anonymiser les données personnelles collectées, afin de réaliser des statistiques.
Comment anonymiser des donnés ?
L’anonymisation des données s’avère être dans la majorité des cas plus complexe que la pseudonymisation.
En effet, pour s’assurer de l’efficacité d’un processus d’anonymisation, les autorités de protection des données européennes ont défini trois critères qui permettent de s’assurer qu’un jeu de données est véritablement anonyme :
- L’individualisation : il ne doit pas être possible d’isoler un individu dans un jeu de donnée.
- La corrélation : il ne doit pas être possible de relier des ensembles de données distincts qui concernent un même individu.
- L’inférence : il ne doit pas être possible de déduire de façon quasi-certaine de nouvelles informations sur un individu.
La CNIL identique, qu’à « défaut de remplir parfaitement ces trois critères, il doit être démontré, via une évaluation approfondie des risques d’identification, que le risque de réidentification avec des moyens raisonnables est nul. ».
Choisir entre la pseudonymisation et l’anonymisation
Ces deux techniques ne permettent pas d’atteindre les mêmes objectifs. Là où la pseudonymisation constitue une simple mesure de sécurité, l’anonymisation permet de se décharger des obligations du RGPD. Le choix de l’une ou l’autre de ces deux techniques dépend en grande partie des finalités pour lesquelles les données ont été collectées, mais aussi de la nécessité ou non de conserver des données personnelles. Alors que la pseudonymisation s’applique aux traitements qui nécessitent une réidentification ultérieures des personnes, l’anonymisation concerne les situations qui permettent d’atteindre l’objectif poursuivi par le traitement de données non identifiables.